Originally, I wanted to write directly about Metadata Management Solution and just briefly mention the definition of metadata. While writing, however, I realized that the concept of metadata is not as straightforward as it may seem at first glance, and its clarification deserves a separate post.
What are Metadata?
Metadata are data about data. Data are objective facts or observations. (more about data in the post here) For example, consider a situation where we observe a large white animal. A large white animal exists, it is an objective fact. Let’s add context to the situation. We work at the polar station, where we observe polar bears—large white animals. Metadata are then the information which helps us to organize and classify our observations, such as the scientific classification, the place of the observation, or the body dimensions of the animal. They allow us to work better with data—to find them, organize them and better understand them.

“Metadata (from Greek meta- = between, behind + Latin data = what is given) data that provides information about other data”
merriam-webster.com
The example of a polar bear as data and data on its observation and classification as metadata is an extreme understanding of metadata concept in the most general sense of the word.
Metadata are all around us and we create a lot of them every day. Here are some examples.
- Book: table of contents, title, author, ISBN
- Photographs: place and time of image capture, type of camera, author
- Email: name, recipient, date
- Blog post: title, author, date of publication
- Database: data format, number of null values for a specific attribute, number of records
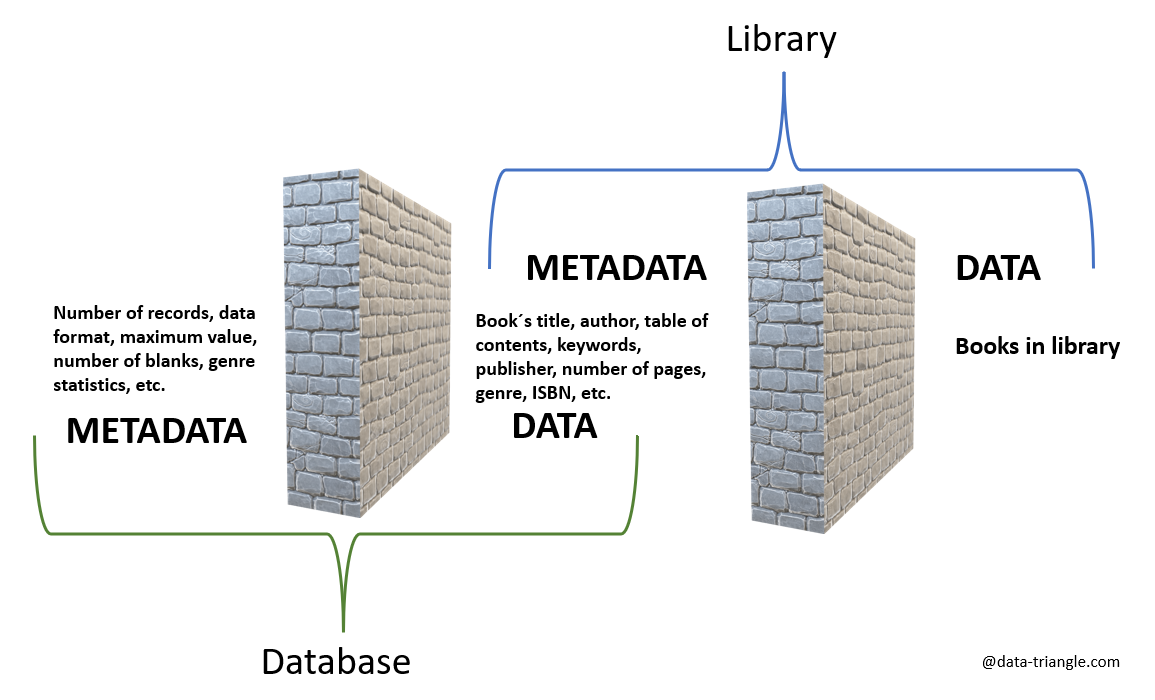
Library and Database
We can exchange the polar bear for another objective fact. We have a book or a library. Imagine the following situation. All books in your library have the same white cover and start on the first page with the first chapter without any additional information. Would it be possible to identify such a book? It would be very difficult and achievable probably only if you have read it in the past. Author, title, year of publication, edition, color, cover style and table of contents are all metadata that help us navigate in our library.
Metadata were traditionally stored in the form of card catalogs and libraries until they were replaced by databases in the 1980s. This change has brought a shift in metadata understanding. In a database, real-world metadata becomes data. They become the object itself. Unlike a library, there are no physical books in the database. The database contains only data. For the librarian, information about the author, genre, and ISBN serves as a starting point for finding a specific book to pass on to the reader. In contrast, a data analyst who works with a library database is unlikely to serve readers. For example, he uses information about the author, genre, ISBN, or number of book borrowings to find out which books are borrowed the most or which genre is currently in demand. He uses the librarian’s metadata as the product itself. For the data analyst metadata are information about the data format of the record, or the number of blank values (e.g. how many books do not have information about the genre)
This is how metadata are understood in an IT environment.
Data:
- ISBN
- Title
- Author
- Date of publication
- Genre
- Number of pages
Metadata:
- ISBN data type
- Total number of books
- Number of books where genre information is missing
- The book with the largest number of pages
- When the record was created in the database
The same is true in a business environment. You will hardly speak about the invoice date as metadata. This is how data and metadata would look like for billing.
Data:
- Invoice number
- Amount
- Customer
- Invoice date
- Due date
Metadata:
- Invoice number data type
- Total number of invoices
- Number of invoices with missing due date
- The largest amount on the invoice
Metadata in Data Analysis
Metadata are essential for working effectively with data. They help us correctly classify the data and then make better use of them. In the field of data analysis, we appreciate metadata especially in the preparation phase of the project, when we need to navigate ourselves in the available data as quickly and efficiently as possible. However project preparation is definitely not only phase where we can use metadata. In various forms, metadata accompanies us throughout the project life cycle. We can also generate metadata ourselves. A good example is monitoring the number of accesses to a specific data analysis output (e.g. report or dashboard). Here, metadata helps us to understand how the report was accepted, how it compares to others, who are our key users. This gives us a good overview of our analytical portfolio and allows us to make better decisions in the future.
There is a thin line between data and metadata. Determining what metadata are depends on the context in which we operate. However, one thing is indisputable. Metadata helps us to understand the world around us.