One of the worst things that can happen to you as a BI developer is when your report gives bad results. You look at the underlying code, which looks fine at first glance, you run it again in the database UI, and the result is suddenly correct. So you update the report and everything is fine. The next day, the report automatically updates the data and the unwanted record is back. Nothing has seemingly changed. The code is still the same, the report settings are unchanged.
If the above happens to you, you most likely have one of non-deterministic SQL functions in your code. Intuitively, even the use of a nondeterministic function should not cause nondeterministic behavior when running an identical script—the execution plan should be the same. With more complex scripts and cloud databases, however, the execution plan is affected by many factors and this issue may occur.
To illustrate how nondeterministic functions work, let’s look at the following code
SELECT order_id, order_date, customer_id,
ROW_NUMBER() OVER(ORDER BY order_date) As RowNum,
RANK() OVER(PARTITION BY customer_id ORDER BY order_date) As Rank,
DENSE_RANK() OVER(PARTITION BY customer_id ORDER BY order_date) As DenseRank
FROM Sales
WHERE customer_id = 1203;
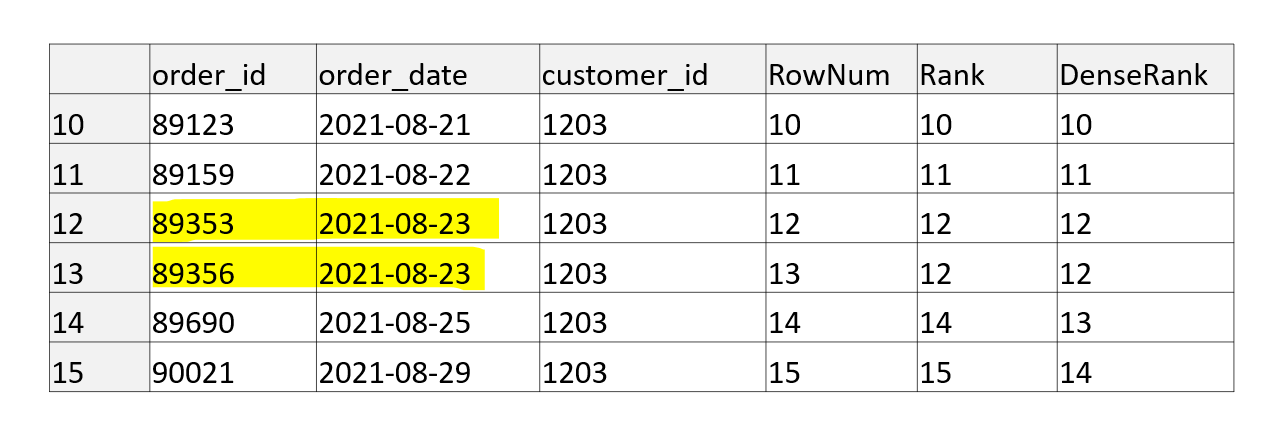
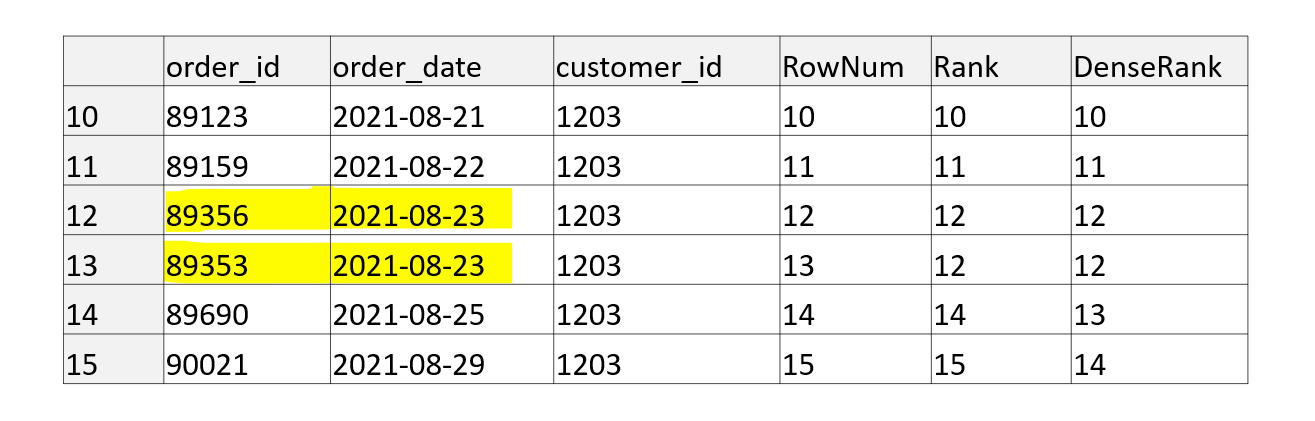
You can see that using the window function ROW_NUMBER, we get a unique order for orders, although order_date, based on which we rank orders, is not unique. The question is whether with the same data and identical window function we can achieve that the order of orders is reversed. The answer is yes, we can, and therefore the ROW_NUMBER function is nondeterministic. In this case, it means that there is no preference between rows with the same order_date. If we add ORDER BY according to order_id (see script below), the order is reversed.
In general, nondeterministic functions do not guarantee the same output when running the same script repeatedly. For deterministic functions, on the other hand, we can be sure that the output will always be the same.
SELECT order_id, order_date, customer_id,
ROW_NUMBER() OVER(ORDER BY order_date) As RowNum,
RANK() OVER(PARTITION BY customer_id ORDER BY order_date) As Rank,
DENSE_RANK() OVER(PARTITION BY customer_id ORDER BY order_date) As DenseRank
FROM Sales
WHERE customer_id = 1203
ORDER BY order_date, order_id DESC;
You can find a list of deterministic and nondeterministic functions here.
Although functions are divided into deterministic and nondeterministic, the real cause of our problem is in the ORDER BY clause. Nondeterministic ordering is one of the common sources of bugs in SQL code. It occurs when ORDER BY does not clearly define the order of the individual lines. In addition to ordering in the window function, classic presentation ORDER BY or TOP / OFFSET-FETCH sorting can cause problems.
For clarity, let’s distinguish between the terms nondeterministic function and nondeterministic ordering
An effective way to eliminate these inconsistencies is to add a unique column to the ORDER BY clause in the window function. In our case, add order_id.
SELECT order_id, order_date, customer_id,
ROW_NUMBER() OVER(ORDER BY order_date, order_id ASC) As RowNum,
RANK() OVER(PARTITION BY customer_id ORDER BY order_date) As Rank,
DENSE_RANK() OVER(PARTITION BY customer_id ORDER BY order_date) As DenseRank
FROM Sales
WHERE customer_id= 1203;
If order_id is the primary key or we have otherwise ensured its uniqueness, the ROW_NUMBER function will now provide us with the same order regardless of the selected execution plan in the database engine. So we don’t have to be afraid to use the ROW_NUMBER function to subset records for the resulting data set. The output will always be the same.